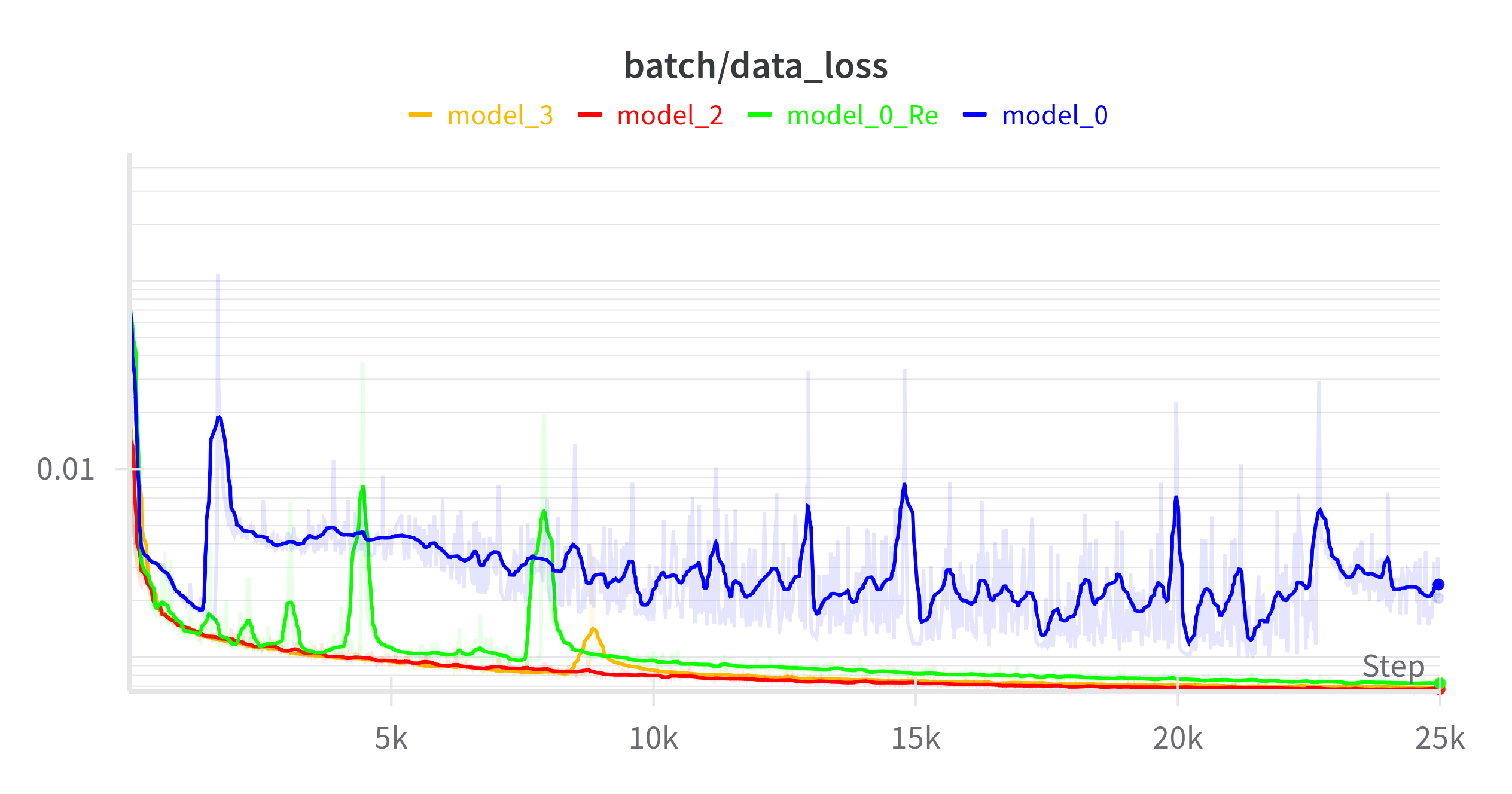
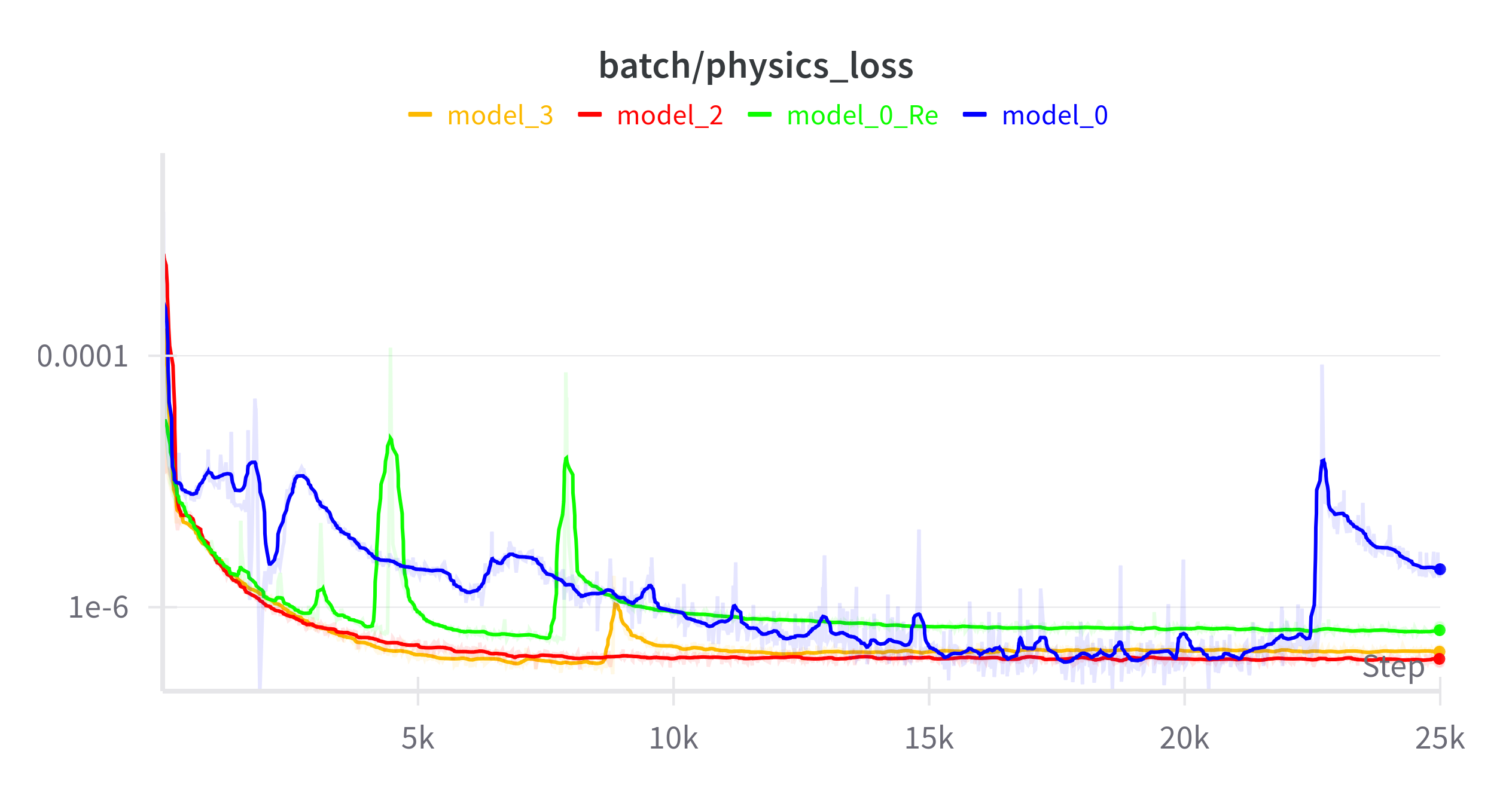
Model 0: Baseline
The original baseline model with basic architecture.
Key Features:
- Basic encoder-decoder architecture
- Simple physics constraints integration
- No specialized handling of Reynolds number
- Tanh activation functions
Architecture Diagram:
Model 0 Re: Enhanced Reynolds Number
Improved handling of the Reynolds number parameter with gradient clipping and momentum.
Key Improvements:
- Clipped gradient for the Reynolds number
- Momentum-based smoothing of Reynolds number updates
- Added BatchNorm layers for stability
- Constrained Reynolds number to physically meaningful range (50-1e5)
Reynolds Number Code:
def get_reynolds_number(self):
clamped_log_re = torch.clamp(self.log_re,
min=torch.log(torch.tensor(50.0, device=self.device)),
max=torch.log(torch.tensor(1e5, device=self.device)))
current_re = torch.exp(clamped_log_re)
if self.previous_re is None:
self.previous_re = current_re
smoothed_re = self.re_momentum * self.previous_re + (1 - self.re_momentum) * current_re
self.previous_re = smoothed_re.detach()
return smoothed_re
Model 1: Modified Dropout
Introduction of dropout layers for improved generalization.
Key Changes:
- Added dropout layers (p=0.2) for regularization
- Positioning of dropout after activation functions
- Maintained Tanh activation functions
- No changes to Reynolds number handling
Note: This model has suboptimal dropout placement which was corrected in Model 2.
Model 2: Optimized Architecture
Significant architectural improvements including residual connections and proper dropout placement.
Major Enhancements:
- Added residual connections (ResBlocks) for better gradient flow
- Switched from Tanh to ReLU activations
- Proper placement of dropout layers
- Improved Reynolds number handling with clipping and momentum
- Added BatchNorm for more stable training
ResBlock Implementation:
class ResBlock(torch.nn.Module):
def __init__(self, in_channel):
super().__init__()
self.conv_block = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=in_channel,
out_channels=in_channel,
kernel_size=3,
stride=1,
padding='same'),
torch.nn.BatchNorm2d(in_channel),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=in_channel,
out_channels=in_channel,
kernel_size=3,
stride=1,
padding='same'),
torch.nn.BatchNorm2d(in_channel)
)
self.act = torch.nn.ReLU()
def forward(self, input):
out = self.conv_block(input)
out += input
out = self.act(out)
return out
Model 3: Neural Network for Reynolds Number
Advanced model with a dedicated neural network for estimating the Reynolds number.
Key Innovations:
- Neural network to predict spatially-varying Reynolds number
- Reynolds number estimated from local flow conditions (u, v)
- All improvements from Model 2 maintained
- More physically realistic modeling of turbulence
Reynolds Network:
class ReynoldsNetwork(nn.Module):
def __init__(self, hidden_dim=16):
super().__init__()
self.re_net = nn.Sequential(
nn.Conv2d(2, hidden_dim, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(hidden_dim, hidden_dim, kernel_size=3, padding=1),
nn.ReLU(),
nn.Dropout(p=0.2),
nn.Conv2d(hidden_dim, 1, kernel_size=3, padding=1),
nn.Sigmoid() # Ensure positive output
)
def forward(self, u, v):
inputs = torch.stack([u, v], dim=1)
re = self.re_net(inputs)
# Scale output to a reasonable range for Reynolds number
re = re * (1e5 - 50.0) + 50.0
return re